

И все списками, списками, списками… Сотнями списков на сотни страниц! И если что забудешь, упустишь малость какую-нибудь, то из-за нее может случиться катастрофа. Как в том стишке про гвоздь и подкову!
Публикация продолжает обсуждение вопросов взаимодействия информационных систем и систем управления, которое было начато в предыдущем материале и начинает анализ информационных конструкций систем управления, к которым относятся списки, документы и т.д. Под списками здесь понимаются не соответствующие структуры данных языков программирования и не части схем баз данных. Здесь рассматриваются списки, которые окружают нас в жизни, например, список жильцов дома, список премированных сотрудников. Понимание роли списков в управлении позволит правильно организовывать взаимодействие с ними информационных систем.
Смотри другие публикации из цикла «По следам забытого РЕГОСС»:Информационные системы; Классификаторы для управленческих списков; Приложение 1. Паутина балансодержателей; Приложение 2. Имущество. Часть 1; Приложение 2. Имущество. Часть 2.
Роль списков в управлении
Оглавление
- Причем тут треугольник Фреге
- Списки – носители управленческого знания
- Список – инструмент управления
- Список – индикатор
- Список – координатор
- Характеристики списка – следы управленческих функций
- Идентификационная путаница
- Попытки синтеза противоречий
- Критерии правильности элементов списка
- Соединения списков
- Формальные свойства совместимости списков
- Обеспечение совместимости списков
- Семантика информационного пространства
- Управленческая сеть списков
- Базы данных, как хранилища списков
- Ложка дёгтя
Причем тут треугольник Фреге
Анализ роли списков в управлении требует предварительных пояснений, которые и изложены в этом разделе.
Алексей Федорович Лосев в своей работе «Философия Имени» [27] подчеркнул, что в слове, а особенно в имени сосредоточено «все наше культурное богатство», что слова являются результатом мысли, т.к. заключают в себе осмысленные факты. Поэтому Алексей Федорович делает вывод, ‑ бессловесное мышление в принципиальном понимании этого выражения есть отсутствие мышления вообще, недоразвитость мышления.
Осмысленные факты используются в последующих актах понимания, для обозначения которых может быть назначено новое имя. Так слова, выстроенные в порядке осмысления фактов, становятся метками эволюции развития нашего знания.
Для большей наглядности этого тезиса прибегнем к метафоре – притче, которую привел Герберт Саймон предваряя главу «Эволюция сложных систем» своей книги «Науки об искусственном» [5].

Теперь представьте, что детали в притче – это имена, а часы новая мысль, которую надо сформулировать. Для большей наглядности напомним, что текст объемом в 1000 слов занимает примерно две с половиной страницы при условии, что использован шрифт Times New Roman 12 размера. При этом речь идет о 1000 имен, которые нужно объединять в связанные предложения. Если не формировать из тысячи исходных имен промежуточные имена- блоки, то изложить нашу мысль будет очень трудно. Хуже того, ее будет трудно понять или вспомнить даже автору. Представьте себе, что в доказательстве теоремы Пифагора вам постоянно приходится включать определение треугольника, квадрата, или, что еще хуже заново формулировать и давать обоснование аксиомам Евклида. Это Сизифов труд, т.к. ваше доказательство будет постоянно «разваливаться», как часы Темпуса.
Для использования осмысленного факта недостаточно знать только его имя, поэтому в логике его принято представлять тройкой: знак, смысл, значение [18]. Эту тройку часто называют треугольником Фреге в честь Готлоба Фреге впервые попытавшегося найти универсальную формулу для описания осмысленного факта. Здесь знак – это имя, например, «город Москва», «город Красноярск». Значение – объект или предмет, на которой указывает имя, например, город Москва, город Красноярск. А вот со смыслом знака или имени все немного сложнее. Например, мы может писать имя «город Красноярск», подразумевая административный центр Красноярского края или крупнейший населенный пункт на реке Енисей, двенадцатый по численности город миллионник по состоянию на 2019 год.
Смысл слова (имени, знака, термина, слова) проявляется в информационных системах порой весьма неожиданно. Чаще всего задумываться о смысле терминов тогда, когда занимаешься проектированием интеграционной 6азы данных, т.е. базы данных, которую должны одновременно использовать несколько приложений [2 стр. 26], или разработкой информационного взаимодействия между различными приложениями с собственными базами данным.
Термин «имя» («имя собственное») часто используют, когда хотят указать, что оно относится к единственному значению, как в случае городов Москва или Красноярск. Когда же знак используемся как обобщенное название группы объектов предметов, то вместо термина «имя» используют термин «понятие» [18,20,20]. В отличие от Готолоба Фреге Евгений Казимирович Войшвилло определял понятие как «смысл слова» [37 стр. 90]. В дальнейшем термин «понятие» используется в трактовке Войшвилло, но думается, что приверженцы определения Фреге вряд ли столкнутся с трудностью в понимании изложенного.
Оба автора с понятием связывают множество предметов, которые подходят определение понятия, а также количество таких предметов. Количество предметов, которые подходят под определение понятия называют его объемом. Так понятия «недвижимость» и «государственная недвижимость» оба в качестве значений принимают объекты недвижимости, но имеют разные объемы, т.к. государству принадлежат не все объекты недвижимости.
С каждым понятием связан некоторый предикат (функция), который определяет подходит предмет под понятие или нет. Предикат часто представляет собой формулу из связанных и свободных переменных объединенных между собой арифметическими и логическим и другими операциями. Знатоки языка Python могут представить себе, например, лямбда-функции. Связанные переменные функции – это свойства (характеристики) предметов, на которые накладываются ограничения, позволяющие считать предмет относящимся к понятию. Такие переменные называются признаками понятия. Например, признаками здания являются наличие у строения стен и кровли [42 стр. 390].
К проблеме наличия разного смысла одинаковых терминов в различных информационных системах придется обращаться еще не раз. А пока ограничимся лишь несколькими примерами: «технические характеристики недвижимости», «права собственности на недвижимость», «государственная (муниципальная) собственность», «земельные участки и расположенная на них недвижимость».
Списки – носители управленческого знания
Но, вернемся к спискам. Начнем с того, что каждый элемент списка – это осмысленный факт, который является результатом изучения неким экспертом первичных документов, сгруппированных в толстые папки, что делает его наименьшим сконструированным управленческим информационным блоком. А сам список соответствует понятию, обладающему некоторым объемом предметов, обозначенных именами собственными [18].
Итак, в основе списка лежит понятие. Особенностью которого является его способность путем создания дочерних списков отражать порядок осмысления управленческих фактов, и тем самым приводить к управленческому решению. Т.е. списки подобно понятиям и именам являются метками эволюции управленческого или организационного знания [3].
Спискам, как и понятиям, построенным по принципу от общего к частному, можно поставить в соответствие ограничение или условие принадлежности предметов списку, выраженное в виде признаков. Специалисты в области логики называют условие предикатом, предикативной функцией или просто функцией.
Собственно, условие принадлежности списку это правило выделения части из общего. Например, студенты СФУ (Сибирского Федерального университета), или многоэтажные здания, где «СФУ» и «многоэтажные» и есть признаки помещения в эти списки студентов и зданий соответственно.
Третьей составной частью списков является набор характеристик, например, «фамилия», «имя», «пол», «дата рождения» для студентов СФУ, значения которых образуют свойства студентов. Среди характеристики могут быть те, которые участвуют в описании условия принадлежности к списку, но чаще всего такие характеристики в список не включаются, а подразумеваются. Наличие характеристик позволяет описывать условия выбора из списка не только языковыми, но и формальными средствами. Так, например, список студентов СФУ призывного возраста можно создать с помощью формулы, накладывая ограничение на возраст, вычисленный через разницу в годах между текущей датой и датой рождения. В результате выбора формируется новый список-понятие, для которого условиями принадлежности являются объединение условий принадлежности с условиями выбора из исходного списка.
Как видно список во многом соответствует определению понятия. Но, не во всем. Т.к. список объединяет в себе не только имя и понятие, но и полный набор значений – элементов списка. Поэтому принадлежность объекта (предмета) списку может быть установлена как с помощью условия в форме функции, так и путем поиска соответствия свойств этого объекта элементам списка. Здесь следует заметить, что качество последнего метода зависит от полноты и актуальности множества элементов списка.
Окончательно, список ‑ это совокупность имени, понятия с набором характеристик, на которые наложены условия, а также полного набора своих значений.
Особую роль в обработке списков играет поиск элементов, который применяется как для определения принадлежности списку, так и для создания новых списков.
Список – инструмент управления
Итак, разобравшись с ролью списков, в качестве блоков управленческого (организационного) знания, а также их структурой, следует рассмотреть их роль в повседневной организационной деятельности. В притче опущено еще одно преимущество блоков – с ними часто могут уже работать не только мастера, но и подмастерья. В еще большей степени этим свойством обладают списки.
Благодаря тому, что список содержит в каждой записи значения ее характеристик, знание в форме списка приобретает преимущество перед традиционными понятиями в том, что список возможно обрабатывать формальными методами. Действительно, для того чтобы включить объект (здание, памятник, достопримечательное место и т.д.) в список объектов культурного наследия должна быть проведена историко-культурная экспертиза. Т.е. оценку исследуемому объекту должны дать специалисты, обладающие специальными экспертными знаниями. Но для того, чтобы выбрать из списка объектов только здания, достаточно обладать самыми общими навыками обработки произвольных списков.
Т.е. приведение управленческих (организационных) знаний к форме списков снижает требования к уровню экспертных знаний сотрудников, которые используют эти списки в своей оперативной деятельности. А значит, список создает возможность разделения труда в сфере управленческой (организационной) деятельности, и как следствие, создает основу для увеличения производительности управленческого труда.
Список – индикатор
Главной целью составления списка является выделение объектов (предметов) учета в особую группу. Например, из отдельных жильцов города составляют список очередников на получение муниципального жилья. После этого любой человек, глядя на этот список может узнать имеет ли он (его родственник, знакомый) право на предоставление муниципального жилья. Или муниципальное имущество записывают в реестр муниципального имущества, тем самым, выделяя его из всего имущества, находящегося на территории муниципалитета. Благодаря этому списку, можно заключить, что собственником объектов, включенных в него, является муниципальное образование, и идти со своими проблемами, касающимися объектов из этого списка, нужно в администрацию этого муниципального образования.
В этом месте следует заметить, что органы государственного (муниципального) управления часто вместо термина «список» используют термин «реестр», подразумевая при этом что данные реестра обладают особым юридическим статусом, в отличие от данных простого списка. И тем не менее в дальнейшем изложении термины «список» и «реестр» считаются синонимами.
Таким образом, список-реестр является неким механизмом, идентифицирующим объект и/или его свойство. Если объект упоминается в списке, то он обладает свойством, если не упоминается, то он этим свойством не обладает.
Присутствие объектов в некоторых реестрах идентифицируют их не только в системе управления, но и в жизни. Так, например, абитуриент, увидев себя в списке зачисленных в ВУЗ, понимает, что стал студентом. А отсутствие о тебе, читатель, записи государственной регистрации актов гражданского состояния (ЗАКС), означает, что ты не живешь (грустная шутка). Такую же роль играют Единый государственный реестр юридических лиц (ЕГРЮЛ), или список работников завода с их табельными номерами. Другие реестры составляются с целью придать составляющим их объектам особые свойства или права. К таким реестрам можно отнести реестры государственного и муниципального имущества, различные списки граждан-льготников и т.д.
Решение задачи идентификации объекта по списку может оказаться непростым делом либо из-за недоступности списка, либо из-за сложности поиска в нем записи об объекте. В этом случае организации, ответственные за ведение реестра, предоставляют заинтересованному лицу (заявителю) специальный документ – выписку. Выписка юридически подтверждает наличие в списке записи об объекте, а также сообщает заявителю основные характеристики объекта. Если же записи об объекте нет в списке, то заявителю выдается письмо об отсутствии записи об интересующем его объекте. Примерами таких выписок являются выписки из технического паспорта квартиры, из единого государственного реестра земель (ЕГРЗ), единого государственного реестра прав (ЕГРП).
Список – координатор
Свойство списков идентифицировать объекты создает условия для координации деятельности различных людей, подразделений в организации, нескольких органов управления, и даже нескольких стран.
Как только молодые люди попали в список студентов учебного заведения, им уже можно прислать приглашение на процедуру распределения по учебным группам. Таким образом, список принятых в учебное заведение абитуриентов определяет дальнейшие действия администрации этого учебного заведения.
Объект, указанный в реестре государственного имущества, может быть сдан в аренду или передан на правах хозяйственного ведения государственному предприятию, и, как результат, позволяет сотрудникам отдела аренды или отдела управления организациями готовить договор аренды или приказ на передачу такого объекта в хозяйственное ведение предприятия. Более того, реестр государственного имущества координирует деятельность юристов, экономистов, сотрудников отделов приватизации в рамках органа власти, ответственного за управление государственным имуществом.
Адресный реестр города Красноярска координирует деятельность почтовых служб, служб доставки, скорой помощи, пожарной команды, милиции, избирательных комиссий, а также многих других организаций города, которые ведут учет объектов недвижимости или мест проживания граждан.
Характеристики списка – следы управленческих функций
Прежде чем выслать приглашение на некое закрытое мероприятие ответственный исполнитель должен удостовериться, что адресат присутствует в списке приглашенных. Прежде чем передать объект казны предприятию служащий орган по управлению имуществом должен убедится, что запись об этом предприятии присутствует в соответствующем реестре имущества. Если человек значится в списке людей, обладающих лицензией на проведение экспертных работ, то он может претендовать на то, чтобы с ним заключили соответствующий договор, а служащий со своей стороны имеет право не препятствовать заключению такого договора.
Таким образом список – инструмент принятия управленческих решений. Когда служащий хочет удостоверится в статусе интересующего его объекта, он в первую очередь пытается выяснить присутствие или отсутствие в списке записи об этом объекте. Наличие нужной записи в списке обычно означает возможность дальнейшей работы с найденным объектом. Отсутствие нужной записи в списке означает отказ от дальнейших действий.
Список в этом случае позволяет распознать (идентифицировать) объект как пригодный или непригодный для дальнейших действий.
В представлениях многих программистов идентификационную функцию списка обеспечивает «айдишник», т.е. некий числовой код записи (суррогатный ключ в теории баз данных) записи. Тогда как для большинства пользователей это набор характеристик элемента в списке (далее идентифицирующие характеристики). Для того, глядя в список можно было найти информацию о человеке, список должен содержать, как минимум, фамилию, имя, отчество, дату рождения, совокупность которых и позволяют идентифицировать этого человека в списке. Для того, чтобы узнать, где расположен дом, в котором проживает человек, необходимы, как минимум, названия населенного пункта, улицы, а также номера дома. Т.к. определить адрес по коду «0f95ec62-a8dd-42e4-8382-68bf91f1d1e6» может только посвященный в тайны федеральной информационной адресной системы (ФИАС).
Другими словами, совокупность значений идентифицирующих характеристик каждого элемента списка должна быть уникальна и это свойство обеспечивает возможность пользователю найти нужный ему элемент списка.
Идентифицирующие характеристики делятся на две группы. Первую группу составляют характеристики, совокупность значений которых составляют признаки списка как понятия. Вторую группу составляют идентифицирующие характеристики отдельных элементов списка.

Рис. 1. Признаки в идентифицирующих характеристиках. Приказ Минфина России от 02.07.2010 № 66н «О формах бухгалтерской отчетности организаций»
Рис. 1 на примере формы отчета о целевом использовании средств иллюстрирует обе группы идентифицирующих характеристик. Из этого примера наглядно видно, что первая группа характеристик имеет неизменные значения для всех записей списка. По этой причине эти общие характеристики и их значения часто не включат в каждый элемент списка, а просто держат их в уме. Такие укороченные списки легче воспринимаются пользователями, но они же могут создавать серьезные проблемы, когда возникает необходимость соединения их с другими списками.
Но главной причиной отсутствия характеристик первой группы в элементах списков является то, что принадлежность списку определяется наличием в нем соответствующего элемента, а не наличие в элементе признаков, определяющих понятие списка. Т.е. признаки принадлежности списку следует воспринимать, как некое правило проверки обоснованности включения или отсутствия элемента в списке.
В дополнение ко всему идентифицирующие характеристики списка определяют его место структуре взаимосвязанных списков, которую с подачи
Эрика Эванса [1] теперь принято называть агрегатами. Явное и неявное различие агрегатов, которым принадлежат два списка, как и отсутствие в них идентифицирующих характеристик первой группы, создают препятствия для их соединения.
Набор идентифицирующих характеристик списка должен быть полным, т.е. гарантировать что одной записи списка соответствует только один реальный объект. Иначе в новостях нет-нет да услышите, что одни человек наделал долгов, а с другого требую их возвращения. Да что там долго ходить. Автору этих строк приписали несуществующее посещение поликлиники и несуществующую болезнь в личном кабинете на портале государственных услуг. Причина этого казуса в том, что идентифицирующими характеристиками в списке посетителей поликлиники были фамилия и инициалы. А вот более свежий пример, «Жительницу Красноярска принуждают платить по долгам ее тезки из Уфы». Как сказано в заметке, ‑ «исполнительные производства пока возбуждают по ФИО, дате и месту рождения. А если данные совпадают, то… сами понимаете, попасть может практически каждый».
Как следует из предыдущих рассуждений полнота характеристик списка может быть абсолютной и относительной. Набор идентифицирующих характеристик обладает абсолютной полнотой, если он содержит в себе все характеристики первой группы, и относительной полнотой в противном случае.
Если к полному набору идентифицирующих характеристик добавить одну или более характеристик, то новый набор не потеряет свойства полноты. Но дополнительные характеристики окажутся избыточными с точки зрения идентифицирующей функции списка. Таким образом набор идентифицирующих характеристик списка должен быть минимально возможным, например, для того чтобы и человек, и компьютер, если список электронный, как можно быстрее справлялись с задачей поиска в списке. Другими словами, набор идентифицирующих характеристик должен быть минимальным, т.е. состоять из минимального числа характеристик, которые в совокупности не теряют свойства полноты.
Набор характеристик почти любого списка значительно шире, чем набор его идентифицирующих характеристик. Объясняется это тем, что список применяется не только для записи о внешнем объекте, но и для решения обратной задачи – поиска объекта или объектов по записям списка. Например, в списке земельных участков можно искать свободный участок под строительство здания. В этом случае список участков должен содержать характеристики, по которым можно установить свободные, т.е. не занятые другими строениями, земельные участки, на которых законы Российский Федерации позволяют строить здания. Можно привести примеры и попроще, найти свободные места в зале, где будет проходить концерт. Найти студентов, сдавших сессию на отлично, чтобы назначить им повышенную стипендию, и т.д.
Как видно из примеров, каждая дополнительная характеристика в записях списка появилась в связи с необходимостью в решении одной или нескольких управленческих задач. Тем не менее полный набор характеристик списка отвечает отвечает принципу минимальной длины [23 стр. 9] – минимальное количество характеристик необходимое для решения задач организации, владеющей списком.
Так, характеристики списка, выражаясь в терминах Акаткина и Ясиновской [21], обеспечивают свойство интероперабельности списка.
Идентификационная путаница
В рассуждениях об идентифицирующих характеристиках легко запутаться. Действительно, за идентифицирующие характеристики можно принять как реестровый или порядковый номер списка, так и иной идентификатор записи списка. А знатоки баз данных могут наверняка вспомнят еще и о ключах таблиц.
Путаница возникает тогда, когда термин «идентификатор» не дополнятся указанием на то, что собственно он идентифицирует, т.е. на что указывает. Вряд ли можно оспаривать существенное различие между предметом и тем местом, где этот предмет распложен. Например, книга и полка в шкафу, или здание и его адрес.
Часто указать на место расположения предмета проще, чем перечислять другие свойства, по которым можно его узнать. Например, говоря о доме, легче указать адрес, по которому он расположен, чем описывать его этажность, материал стен и т.д.
Точно так же легче указать на место записи в списке, чем описывать, о чем она. Поэтому в нашей жизни мы окружены номерами записей в списках такими как: номер и дата актовой записи о нашем рождении, реестровый номер записи о праве на квартиру, кадастровый номер земельного участка, ОГРН (основной государственный регистрационный номер юридического лица) или ОГРНИП (основной государственный регистрационный номер индивидуального предпринимателя) и т.д.
Не зря говорится – палка о двух концах. Простота указания на запись вместо описания человека, объекта или предмета, о которых идет речь в этой записи оборачивается проблемами, когда:
- в запись внесены ошибочные или неверные сведения;
- записи из одного списка необходимо сопоставить запись из другого списка.
Причина этих проблем в том, что по значению идентификатора записи ничего нельзя сказать об объекте, который ей описывается. Действительно, если в записи указано имя, будь то Иван, Марья, Настасья или Николай, уже можно делать вывод о частичном соответствии записи реальному человеку. Если этого человека зовут не так, как указано в записи, то либо запись содержат данные о другом человеке, либо в неё закралась ошибка. И по мере увеличения таких характеристик уверенность в правильности или ошибочности записи списка только растет.
Но глядя на цифровые значения ИНН (идентификационный номер налогоплательщика) или СНИЛС (страховой номер индивидуального лицевого счета), ничего нельзя сказать о соответствии содержащей их записи конкретному человеку. Если предыдущий аргумент показался недостаточно убедительным, то посмотрите на этот идентификатор записи об адресе ФИАС «0f95ec62-a8dd-42e4-8382-68bf91f1d1e6».
Значения ИНН и СНИЛС не более чем идентификаторы места хранения сведений в налоговой службе или пенсионном фонде. Даже в тех случаях, когда значения идентификаторов записей имеют сложную структуру, например, в первых четырех символах ИНН указан код налоговой инспекции.
Как бы ни создавался идентификатор записи, он указывает только на место в списке, где хранятся данные. В то время как идентифицирующие характеристики позволяют распознать объект (предмет), который соответствует записи списка.
Отличительным свойством идентифицирующих характеристик является возможность использования их значений при проверках, подтверждении или опровержении соответствия записи списка объекту (предмету). Вслед за Рудольфом Карнапом и Карлом Р. Поппером эти свойства часто называют верифицируемость (подтверждаемость) и фальсифицируемость (опровергаемость).
Таким образом, лишь наличие идентифицирующих характеристик делает список принципиально соединимым с другими списками, обладающими подобными идентифицирующими характеристиками. Другими словами, наличие идентифицирующих характеристик в списке является необходимым условием его соединимости.
Попытки синтеза противоречий
Напомним суть противоречий. Главное из них в простоте соединения по идентификаторам (номерам) записей в списках по сравнению со сложностью соединения по идентификационным характеристикам. Далее для того, чтобы соединить два списка по идентификаторам их записей, необходима согласованность идентификаторов во всех соединяемых списков. В простейшем случае такая согласованность определяется совпадением номеров записей, относящихся к одним и тем же объектам.
Даже если принципиальная соединимость списков осуществима, дополнительно придется учитывать возможные различия форматов значений одноименных характеристик в соединяемых списках.
Преодолению описанных противоречий посвящены непрекращающиеся попытки стандартизации значений как идентификаторов записей, так и идентифицирующих характеристик списков, ведущиеся в нескольких направлениях.
Первое направление – создавать общедоступные списки, идентификаторы записей которых может узнать любой желающий. К таким спискам относятся различные реестры федерального уровня. Идея состоит в том, что когда два различных списка включают идентификаторы записей из общероссийских реестров, то они автоматически заимствуют имя, значение и формат идентификатора. И на первый взгляд, соединение этих списков не вызывает затруднений. Такой эффект, например, обеспечивает использование кода ФИАС (Федеральной информационной адресной системы) в различных списках с данными об объектах недвижимости. К сожалению, наличие нескольких записей, а, следовательно, и кодов ФИАС, для одного и того же адреса[*1] порой приводит к соединению записей о различных объектах недвижимости. Кроме того, код ФИАС указывает на запись об адресе в реестре, поэтому невозможно сразу оценить, что с чем соединяется. Приходится верить, и порой разочаровываться.
Ко второму направлению решения задачи соединимости списков следует отнести попытки формализовать значения идентифицирующих характеристик. Анализу этого направления будет посвящена оставшаяся часть этой главы.
Главными препятствиями к использованию характеристик для соединения списков являются:
- большое число характеристик, составляющих полный набор;
- изменчивость полного набора характеристик;
- неопределенность форматов значений нечисловых характеристик.
Влияние неопределенности форматов значений идентифицирующих характеристик можно уменьшить, заменив их значения кодами из специальных классификаторов. Для этого строковое значение характеристики в произвольном формате заменяют буквенно-цифровым, буквенным или цифровым кодом. Кодовые значения каждой характеристики создаются в соответствии с некоторой системой кодирования, которая в свою очередь основывается на системе классификации. Последняя в конечном счете определяет структуру кода.
Поясню на простых примерах. Привычная десятичная форма записи чисел предполагает, что каждая цифра в зависимости от места имеет свой смысл. В числе 123: 1 – это число сотен, 2 – число десятков, а 3- число единиц. Собственно, наглядность десятичной системы исчисления и вдохновляет попытки замены названий различных объектов их кодами.
Еще один пример можно увидеть, открыв любую книгу на 3 или 4 странице, обратив внимание на коды УДК (Универсальная десятичная классификация) и ББК (Библиотечно-библиографическая классификация). Они выглядят вот так: УДК 681.3 и ББК 32.973.
Вот, например, как расшифровывается код УДК 681.3:
- 6: Прикладные науки. Медицина. Техника
- 68: Различные отрасли промышленности и ремесла, производящие конечную продукцию. Точная механика. Легкая промышленность
- 681: Точная механика
- 681.3:(Вычислительная техника. Машины и устройства для обработки данных. Автоматическая обработка данных. Электронные вычислительные машины (ЭВМ). Калькуляторы)
Итак, с помощью классификации и кодирования можно преодолеть трудности с неопределенностью форматов значений идентифицирующих характеристик.
«Платой» за такое решение становится вполне преодолимая трудность понимания кодов, когда нет под рукой классификатора. Условием для соединения двух списков становится требование, чтобы один и тот же классификатор использовался для создания значений соответствующих идентифицирующих характеристик каждого из списков. А это значит, что каждый такой классификатор должен быть известен каждой организации (подразделению) занятой ведением соединяющихся списков. Такими общедоступными классификаторами и справочниками являются общероссийские и отраслевые классификаторы. В европейских странах созданы общие семантические модели данных и базовые словари [21 стр. 343], что видимо позволяет использовать возможности не только отдельных классификаторов, но также взаимосвязи различных классификаторов.
Задача уменьшения числа идентифицирующих характеристик также решается с помощью классификаторов. Например, восьмизначный код классификатора ОКАТО (Общероссийский классификатор объектов административно-территориального деления) заменяет набор из 4-х значений характеристик, идентифицирующий место расположения объекта: «субъект Российский Федерации», «район или город регионального значения», «населенный пункт», «сельсовет». Когда этот код расширен до одиннадцати знаков, то к выше перечисленному набору характеристик добавляется еще «деревни и поселки, подчиненные сельсоветам».
Коды классификаторов не вечны. Одни объекты классификации исчезают, другие наоборот возникают. Вследствие этого исчезают и добавляются новые позиции классификаторов. Особенно это касается классификаторов, коды которых отражают сразу несколько идентифицирующих характеристик. Коды таких классификаторов обладают внутренней структурой, отражающей взаимосвязи между классифицируемыми объектами. Когда связи между реальными объектами изменяются, то изменяется и коды классификатора.
За примером снова обратимся к ОКАТО, коды которого отражают структуру административного подчинения объектов территориального деления земель России. Детально структура кодов ОКАТО рассмотрена в соответствующем документе. Здесь же приведен пример изменения кодов населенных пунктов при изменении их типов, а также при изменении их административной подчиненности.
Таблица ниже содержит сведения о поселках Светлогорск и Поканаевка. У обоих поселков с 2016 по 2020 годы изменился тип с поселка городского типа на поселок сельского типа. По правилам построения кодов ОКАТО это изменение отразилось в 6 (слева) позиции из кода – цифра 5 (город, поселок городского типа) была заменена на цифру 2 (сельсовет). Как результат изменились порядковые номера сельсоветов (позиции 7-8), а также добавились порядковые номера населенных пунктов, подчиненных сельсовету. А вот тип поселков Кедровый, Сосновка, Южная Тунгуска не поменялся, но поменялся статус администрации населенного пункта, которому они подчиняются. Поэтому в кодах этих поселков в 6-й позиции цифра 5 заменена на 2 с последующими изменениями цифр правее 6-й позиции.
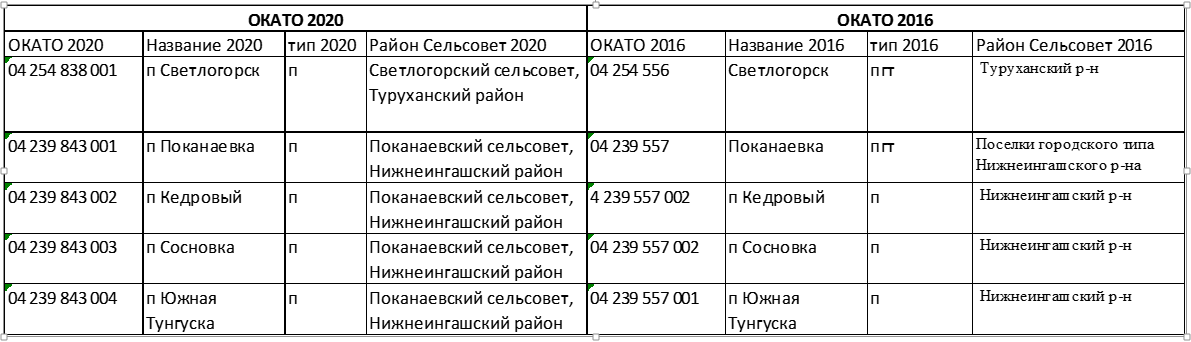
Рис. 2.Примеры населённых пунктов с изменившимися кодами ОКАТО.
Здесь так подробно рассмотрен пример влияния внешних изменений на значение кодов классификаторов для того, чтобы иметь основание оценить реализуемость идеи создания единого универсального классификатора, коды которого создавались бы на некотором универсальном формализованном языке.
Действительно, почему нельзя построить дерево знаний, присвоив номер или буквенный код каждому его узлу, а затем каждое понятие дерева представлять в виде последовательности цифр и/или букв от корня к узлу. Тем более, что подобную мысль высказывал еще Рене Декарт, который считал возможным создание универсального языка при условии, что удастся «перенумеровать и упорядочить все человеческие мысли и идеи естественным образом»[*2].
Даже если такой язык был бы создан то, он не уберег бы коды от их устаревания. Дело в том, что код это не язык, а некоторое сообщение, на языке. Поэтому в таком коде зафиксировано отношение между внешними объектами на момент создания этого кода.
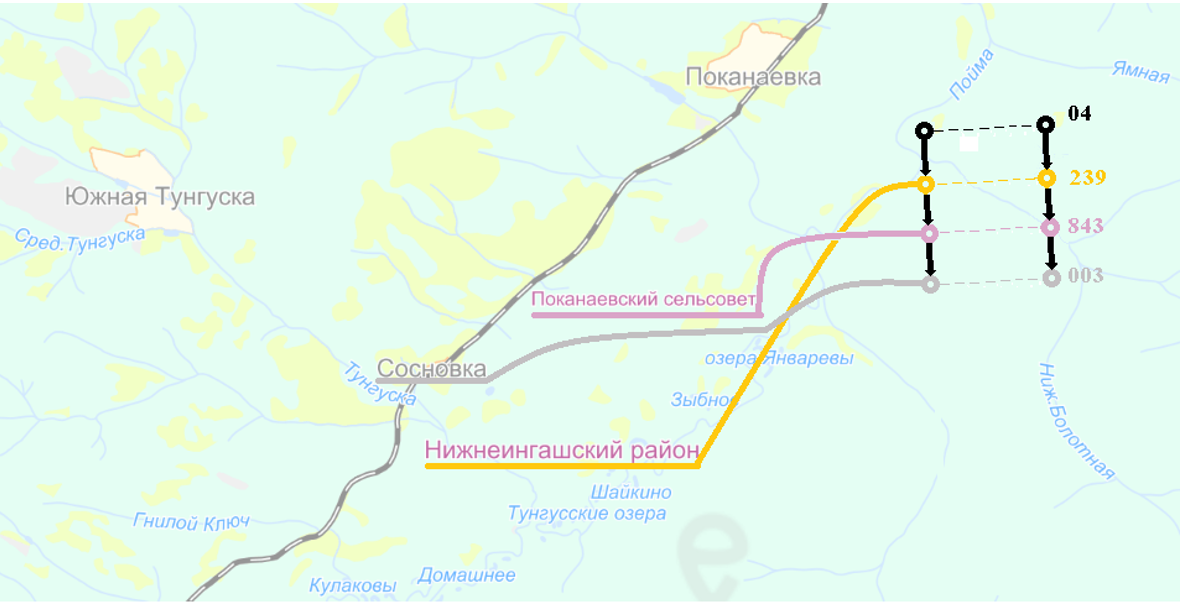
Рис. 3.Административная подчиненность в структуре кода.
(На рисунке использована карта с портала Енисей-ГИС)
Так на Рис. 3 показано, как административная подчиненность района, сельсовета, и населенного пункта преобразуется в зависимости в последовательность цифр в кода ОКАТО. Значит код должен изменяться непосредственно вслед за оригиналом. Но так как такими изменениями занимается ответственная организация (далее оператор), которая может приводить в соответствие коды классификатора реальным объектам. В результате структура кода перестает правильно отражать зависимости среди объектов-источников, что приводит к образованию, так называемого, окна несогласованности (inconsistency window) [2 стр.70]. И чем продолжительнее это окно несогласованности кода оригинальным объектам, тем в меньшей степени такой код может использоваться как источник подтверждения или опровержения соответствия записи, описываемому ей объекту. В конечном итоге такой неактуальный код превращается просто идентификатор.
Использование в списках кодов даже общеизвестных классификаторов не гарантирует, что эти коды будут одновременно обновляться во всех использующих их списках. Списки ведутся разными организациями, которые могут актуализировать коды классификаторов в разное время. Поэтому даже использование одного и того же классификатора в двух списках может создать сложности в процессе их практического соединения.
Вывод. Использование классификаторов не может полностью заменить идентифицирующие характеристики в списках. И несмотря на необходимость постоянных усилий по актуализации кодов классификаторов в списках, они часто представляют собой хороший компромисс между идентификатором записи и набором значений идентифицирующих характеристик.
В качестве небольшого отдыха от рассуждений о сомнительной возможности создания всеобщей системы классификации и универсального языка предлагаю взглянуть на отрывок из рассказа Хорхе Луиса Борхеса «Аналитический язык Джона Уилкинса».

Критерии правильности элементов списка
Списки могут содержать ошибочно внесенные элементы. И по мере удалении списка от места его создания сомнения ответственных пользователей в правильности внесенных данных могут только нарастать. Поэтому в дополнение к идентифицирующим характеристикам и характеристикам поддержки управленческих функций в список включаются характеристики, позволяющие подтвердить обоснованность нахождения в нем каждого элемента.
Строго говоря, логический критерий правильности элемента списка строится на использовании совокупности признаков списка и идентифицирующих характеристик элемента вместе с их значениями. Но логический критерий не слишком удобен в практической управленческий деятельности. Во-первых, признаки понятия списка почти никогда не присутствуют в элементах списка. Во-вторых, из-за удаленности от источника данных приходится брать на веру значения идентифицирующих характеристик. В-третьих, значения идентифицирующих характеристик анонимны, т.е. не указан сотрудник, создавший элемент списка с этими значениями. В-четвертых, применение логического критерия для подтверждения правильности элемента списка в условиях работы под давлением сроков и требований начальства чревата увеличением количества ошибок.
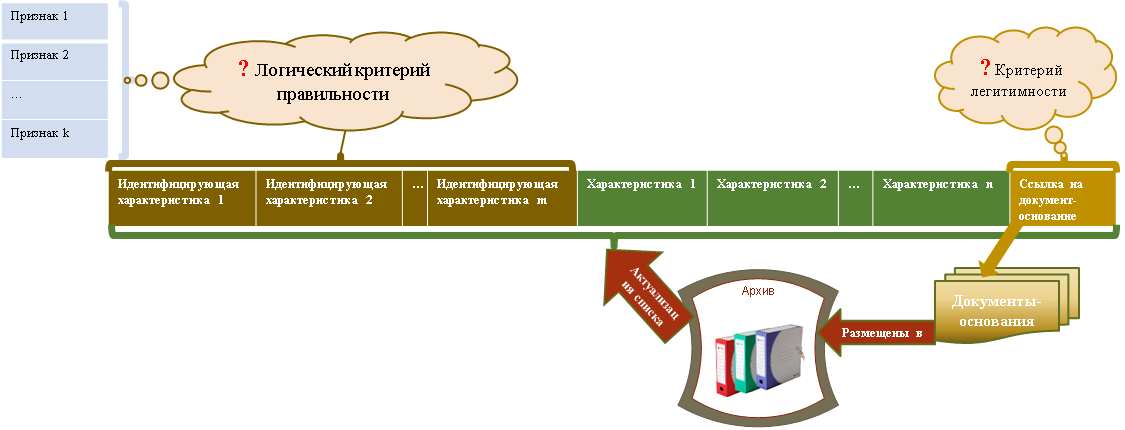
Рис. 4. Характеристики правильности включения элемента в список.
Сложности использования логического критерия для подтверждения правильности состава списка породили новый критерий, назовем его критерием легитимности, в основу которой заложен следующий административный процесс.
Эксперты, отвечающие за выявление объектов, информация о которых могут быть включены в список в виде его элементов, оформляют набор кандидатов. На основе набора кандидатов готовится распорядительный документ за подписью руководителя, содержащий требование включить новые элементы, внести изменения в существующие или аннулировать устаревшие(неверные) элементы списка. К набору характеристик списка добавляется еще одна или несколько характеристик, значениями которых являются основные реквизиты распорядительного документа, который приобретает статус документа-основания для включения элементов в список.
Критерий легитимности еще менее чем логический критерий пригоден для ответа на вопрос о правильности данных элемента списка. Но он явно указывает на ответственных за состояние данных в списке, а иногда и позволяет найти экспертов, которым можно задать вопросы, касающиеся степени актуальности данных списка.
Рис. 4. показывает два канала взаимодействия документов и списков. Анализ прочих каналов их взаимодействия, надеюсь, будет выполнен в следующих публикациях.
Соединения списков
Константин Добромыслов, кандидат экономических наук, доцент РАНХиГС
Следствием принципа минимальности в подходе к формированию списков является различие в составах характеристик списков об одних и тех же объектах от организации к организации (от ведомства к ведомству). Поэтому, когда возникает управленческая задача, требующая знания дополнительных характеристик, то списки приходится соединять.
Что такое соединить два списка? Это значит добавить в каждую запись исходного списка характеристики соответствующей записи внешнего списка. Таким образом, если во внешнем списке может быть найдена запись, соответствующая каждой записи исходного списка, то внешний список будет называться совместимым с исходным. А само это свойство списков будет называться совместимостью списков.
Совместимость списков может быть односторонней, когда внешний список совместим с исходным, но не наоборот. Если оба списка совместимы друг с другом, то их совместимость будут называться двусторонней, а сами списки взаимно совместимыми.
А как устанавливается соответствие записей двух списков? В простейшем случае запись внешнего списка соответствует записи исходного списка тогда, когда идентифицирующие характеристики и их значения записи внешнего списка присутствуют в записи исходного списка. Но даже при этом условии не для каждой записи исходного списка возможно найти одну соответствующую запись внешнего списка. Причиной может служить разная степень детализации данных в элементах списка. Например, один бухгалтер в списке имущества заведет одну запись на весь компьютер, а другой ‑ отдельные записи для системного блока, монитора, принтера и т.д. В этом случае путем группировки характеристик детальных записей можно искусственно создать запись соответствующую обобщенной, но не наоборот.
Рис. 5. Уровни соединения списков.
Причиной различий в детализации списков могут быть не только индивидуальные подходы к учету данных у каждого пользователя, но и разделение (объединение) регионов, населенных пунктов и различных ведомств.
До сих пор совместимость списков рассматривалась как возможность соединения списков, в основе которых положено общее понятие. Например, соединяются данные о площадях помещений и материалах стен с данными об их собственниках для одних и тех же зданий. Такой вид соединения можно представлять, как линейное соединение, при котором результирующий список объединяет в себе характеристики двух и более исходных списков.
Но соединяться могут списки, относящиеся к разным, хотя и взаимосвязанным понятиям. Например, автобусные остановки с характеристиками покрытия и плотностью потока движения на автомобильных дорогах. Идентифицирующие характеристики таких списков совпадают не полностью. Точнее, идентифицирующие характеристики одного списка (например, здания) содержатся в наборе идентифицирующих характеристик другого списка (например, помещений), но для последнего списка они не является полными. В этом случае принято говорить, что понятия объединяют в агрегат (
[1 стр.124], [2 стр.69]).
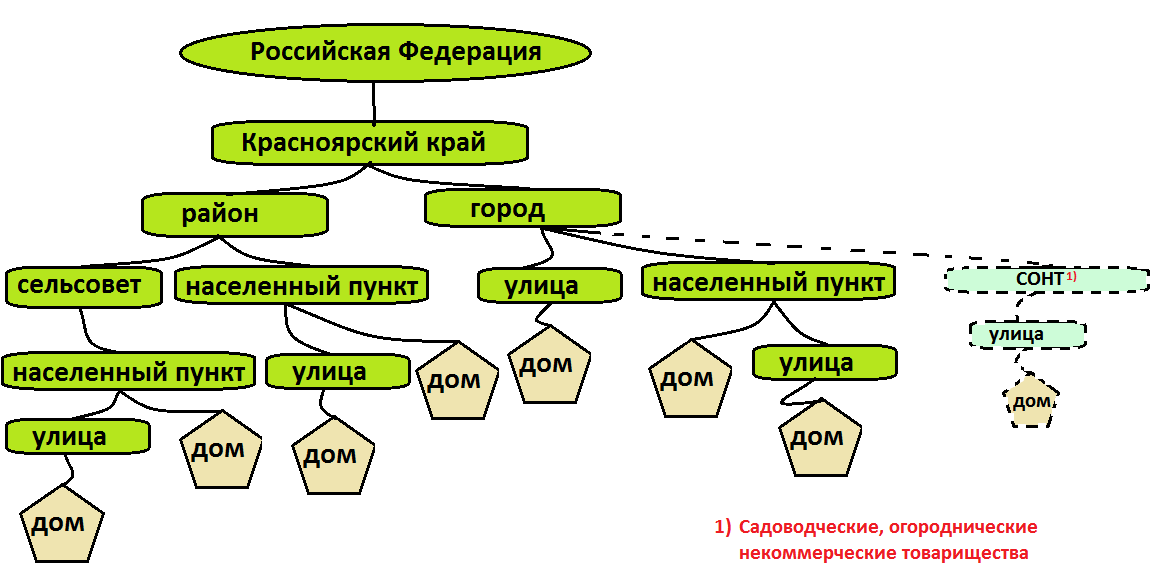
Рис. 6. Пример схемы расширения агрегата «Адресов Красноярского края Российской Федерации».
В отличие от линейного расширения списка в этом случае расширяется объем понятия списка, описанного как агрегат. Рис. 6 иллюстрирует расширение понятия адреса путем объемного соединения классической схемы адресов в населенных пунктах со схемой адресов садоводческих и огороднических некоммерческих товариществ, административно подчиненных городу.
Если совокупность значений идентифицирующих характеристик списка не обеспечивает уникальность каждого элемента списка, то совместимость этого списка с другим также не гарантирует от проблем в процессе соединения. Действительно, когда внешний список содержит несколько элементов с одним и тем же набором значений идентифицирующих характеристик, возникнет неопределенность, в результате которой необходимо принимать решение с каким экземпляром таких элементов следует соединять элемент исходной таблицы.
Совместимость списков не гарантирует от проблем в процессе соединения, например, если внешний список содержит более одной записи с одним и тем же набором идентификационных характеристик, то возникнет неопределенность, т.к. необходимо будет принимать решение с какой из этих записей следует соединять запись исходной таблицы.

Таблица 7. Неоднозначность идентификационных характеристик внешнего списка
Если у читателя закралось сомнение в существовании указанной проблемы, то предлагаю посмотреть записи в Таблица 1.
Записи выбраны из ФИАС у них различные внутренние идентификаторы («7f8d1c96-232a-435c-b943-d4d95d8881d1» и «cfe94d60-c20f-40e9-9267-6d1cdabf88eb», соответственно), но одинаковые идентификационные характеристики. Значение в графе ActStatus равное 0, означает что выбрана актуальная версия записи, т.к. существуют еще и неактуальные записи. И таких групп с повторяющимися идентификационными характеристиками только среди адресов Красноярского края больше 480.
Заметьте, что речь идет о списках, которые ведутся автоматизированным способом, а что говорить о полу-ручных списках.
Формальные свойства совместимости списков

Скачать ФОРМАЛЬНЫЕ СВОЙСТВА СОВМЕСТИМОСТИ СПИСКОВ
Обеспечение совместимости списков
Теперь обратимся к задаче как сделать два списка совместимыми. Первым делом необходимо включить в исходный список все идентифицирующие характеристики внешнего списка, а затем аккуратно в каждую запись исходного списка внести набор характеристик из соответствующей записи внешнего списка. Здесь описана простейшая методика обеспечения совместимости списков, которая отражает техническую или синтаксическую сторону решения поставленной задачи. Но, остается невыясненным вопрос – а всегда ли, т.е. для каждой ли пары списков можно применить методику обеспечения совместимости.
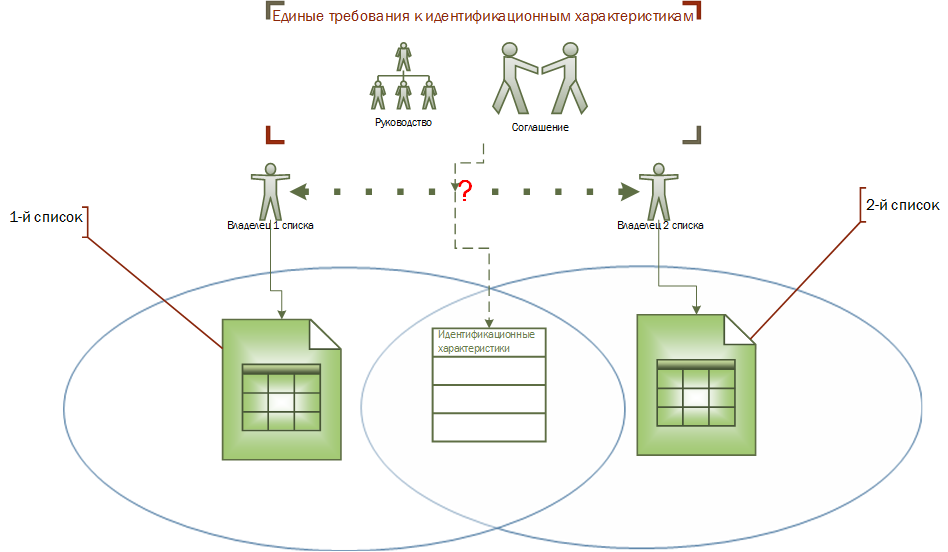
Рис. 7. Надсписковое соглашение.
Во-первых, реальная совместимость списков зависит не только от совпадающего набора идентифицирующих характеристик, но и совпадения значений этих характеристик соединяемых элементов. Совпадение же значений внешнего и исходного списков порой обеспечивается путем дополнительных преобразований. Таким преобразованиями могут быть, например, приведение к одной единице измерения, одному часовому поясу.
Даже если смысл значений в записях двух списков одинаковый, отличаться может форма записи. Вот три варианта названия посёлка Верхняя Бирюса: «Верхн. Бирюса»; «В. Бирюса»; «В-Бирюса». Детский сад часто обозначается словом «детсад». Кроме сокращений слов в текстовых значениях могут встречаться перестановки, например, «1-я Озёрная», «Озёрная 1-я». И много других способов записи одного и того же наименования.
Т.е. для обеспечения совместимости списков нужны «надсписковое» соглашение, которое устанавливает единые требования к заполнению набора значений идентифицирующих характеристик (смотри Рис. 7). Такое соглашение могут заключить владельцы списков или оно может быть утверждено общим для владельцев списков руководителем.
По форме такое соглашение может быть порядком или методикой заполнения идентифицирующих характеристик. Но наиболее эффективной формой реализации такого соглашения является общий классификатор или справочник. В последнем случае порядок и методика заполнения характеристики оказываются реализованными в самом классификаторе, а владельцам списков остается находить нужное значение кода и включать его в запись списка.
Это свойство классификаторов и справочников обеспечивать совместимость списков часто упускается из виду как заказчиками там и разработчиками информационных систем. В результате в качестве общерегиональных или общегородских классификаторов одни предлагают, а другие принимают внутренние справочники отдельной информационной системы. Т.к. большинство таких справочников не применяются в других информационных системах, то они перестают играть какую-либо роль в обеспечении совместимости списков. Более подробно о решении задач совместимости списков с использованием классификаторов и справочников будет сказано в в публикации посвященной классификаторам и справочникам.
Решение задачи обеспечения совместимости списков даже внутри одной организации не всегда оказывается простой из-за наличия внутриорганизационных барьеров, внутренней конкуренции и сложных отношений между различными сотрудниками. Что уж говорить о согласовании списков, принадлежащих различными организациям, отраслевым ведомствам. На межведомственном уровне каждая попытка согласования списков, принадлежащих различным ведомствам дополнительно сталкивается с проблемой выработки единой терминологии, единого толкования и правил использования понятий.
Может быть, кому-то покажется, что проблема межведомственного согласования списков слишком преувеличена, тогда попробуйте каждому лесному участку поставить в соответствие кадастровый номер. Убежден, что эта работа окажется невыполнимой. Причина в том, что полный список лесных участков, скорее всего, нигде не хранится, т.к. единицей учета лесного фонда является лесотаксационный выдел в границах лесного квартала.
Идентифицирующими характеристиками лесотаксационного выдела являются: субъект Российской Федерации, муниципальный район, лесничество, участковое лесничество, номер лесного квартала, номер лесотаксационного выдела. Лесной участок образуется только в момент постановки его на кадастровый учет, что согласно Лесному Кодексу РФ, происходит перед оформлением договора аренды этого участка. Идентифицирующими характеристиками земельного участка при кадастровом учете являются: кадастровый округ, кадастровый район, кадастровый квартал, номер участка.
Как видите, обеспечить совместимость списка земельных участков, имеющих кадастровый номер, и списка лесотаксационных выделов совсем не просто из-за смысловых различий идентифицирующих характеристик этих списков.
Семантика информационного пространства
Рассуждения предыдущего раздела привели к заключению, что задача обеспечения совместимости списков не ограничивается только согласованием наборов идентифицирующих характеристик и утверждением единой методики их заполнения. Поэтому набор требований к среде, обеспечивающей взаимодействие размещенных в ней информационных систем, часто называют общим термином «информационное пространство».
Жаль, что на практике под этим термином понимается лишь возможность доступа одного информационного ресурса такой среды к любому другому ресурсу, расположенному в ней же. А информационным ресурсом в этом случает могут быть электронные сервисы, интернет порталы и сайты, базы данных и справочников и т.д. Но, доступность всех ресурсов информационного пространства не является достаточным условием для обеспечения совместимости списков.
Условием решения задачи обеспечения совместимости списков следует считать создание информационного пространства, как своеобразной комфортной среды, в которой существуют списки, и требования к которой описаны в некотором «надсписковом» соглашении (смотри Рис. 7). Такое соглашение об информационном пространстве могут заключить владельцы списков, оно может быть утверждено общим для владельцев списков руководителем, но часто утверждается на государственном или даже на международном уровне.
Рис. 8. Иллюстрация описания основных понятий информационного пространства.
Структура информационного пространства подробно описана Акаткиным Ю.М., Ясиновской Е.Д. в обзоре «Цифровая трансформация государственного управления: Датацентричность и семантическая интероперабельность» [21 стр. 264] Обзор содержит описание требований к составу информационного пространства в странах ЕС, США и Российской Федерации. Из обзора следует, что потребность в межведомственном и международном обмене данными стало драйвером для расширения масштабов интеграции независимых ИС. В тоже время, «международный опыт показывает, что международный обмен информацией невозможен без формализации предметных областей информационного взаимодействия и стандартизации данных. В результате этих потребностей сформировалось представление об информационном пространстве.
В общем случае такое соглашение об информационном пространстве содержит требования к:
- Наборам основных понятий информационного пространства;
- Описанию метаданных, т.е. схемам описания (названиям, структуре, составу характеристик) основных понятий;
- Моделям данных информационного пространства, порядок заполнения значениями характеристик основных понятий;
- Спецификации и форматам информационных обменов между информационными системами, обеспечивающих взаимодействие краевых ИС, краевых и муниципальных ИС, а также муниципальных ИС;
- Формам представления данных основных понятий;
- Набору и составу общедоступных (базовых) сервисов обеспечивающим доступ к информационным ресурсам, в том числе:
- Картографическим данным и метаданным;
- Классификаторам и справочникам, таким как адреса;
- Набору и составу общих (базовых) классификаторов и справочников.
Для осуждаемой темы достаточно обратить внимание на необходимость присутствия в «надсписковом» соглашении множества понятий, включая набор их обязательных общих и идентифицирующих характеристик, а также признаков, характеризующих каждое понятие и список, созданный на его основе (смотри Рис. 8).
Во-вторых, соглашение для каждого понятия информационного пространства должно содержать должно содержать порядок (методику) заполнения значениями его основных характеристик, и, в особенности, идентифицирующих характеристик.
Ну и, наконец, в-третьих, соглашение должно содержать набор общих (базовых) классификаторов и справочников информационного пространства, выполняющих роль стандартов заполнения значений соответствующих характеристик списков, а также обеспечивающих принципиальную возможности согласования нескольких списков и создания на их основе нового обобщенного (агрегированного) списка.
Управленческая сеть списков
Если в предыдущем разделе обсуждалось соединение списков, которое можно условно назвать соединением по горизонтали, то в этом в этом разделе будет обсуждаться преобразование списков по вертикали, подразумевая под этим термином управленческую вертикаль.

Казалось бы, из однородных, т.е. соответствующих одному понятию, списков, созданных в подразделениях организации легко составить общий список организации, добавив к идентифицирующим характеристикам каждого списка код подразделения, ответственного за его содержание. Но это только на первый взгляд.
Для того чтобы несколько списков объединить в общий список, объединяемые однородные списки должны иметь один и тот же набор характеристик. Заполнение характеристик значениями должно подчиняться единому порядку, с использованием общих классификаторов и справочников.
Таким образом однородные списки получают возможность «передвигаться» вверх по иерархической лестнице управления.
Общий список, как и любой другой, должен отвечает принципу минимальности, поэтому по мере обобщения списка из него исключаются характеристики, которые не соответствуют управленческим функциям нового уровня управления.
Не забудем также, что в основе принципа минимальности списка лежит закон необходимого разнообразия [27 стр.293], который применительно к списку формулируется примерно так – разнообразие характеристик списка должно быть не больше разнообразия характеристик, которое способен контролировать совокупный пользователь списка.
Поэтому, по мере «движения» списков на верхние уровни управления они теряют исходные характеристики, хотя уменьшение исходных характеристик списков не исключает «горизонтального» их соединения.
Замечание
Возможно допустить, что на новом уровне к импортированному от подчиненных списку могут быть добавлены новые характеристики, как результат управленческих функций, которых не было у подчиненных. Но на практике такая организация системы управления маловероятна. Скорее подчиненным подразделениям будет поручено создавать расширенные списки или несколько совместимых списков.
Конец Замечания
Следуя закону необходимого разнообразия, однородные списки из подчиненных подразделений должны не только объединяться в обобщенный список и сокращать число исходных характеристик, но и преобразовываться в новый список, содержащий сводные (агрегированные) данные, например, по подразделениям, территориям, и т.д.
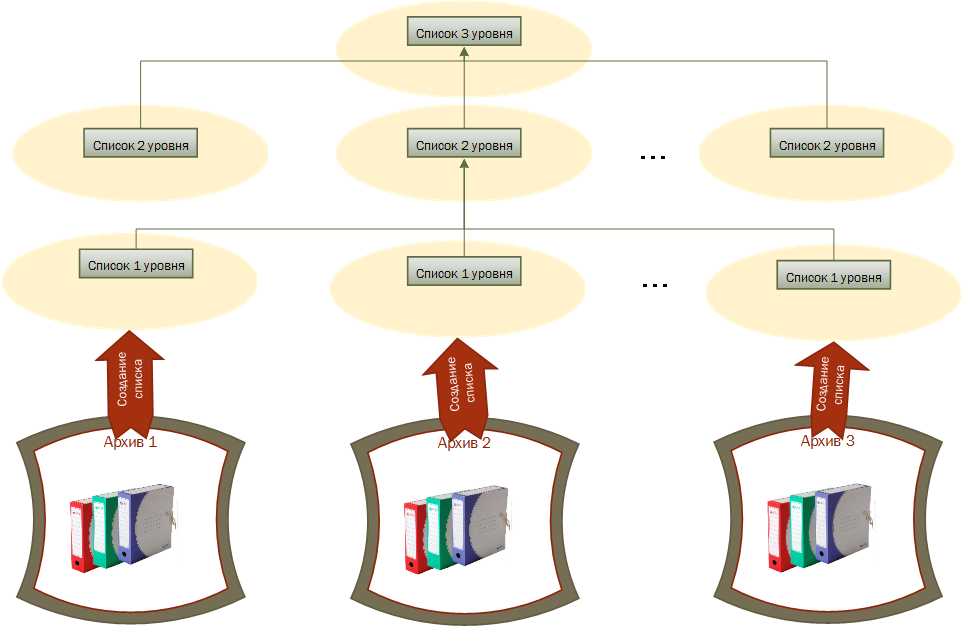
Рис. 9. Движение списков в иерархии управления.
Таким образом однородные списки становятся своеобразным инструментом поддержки иерархии управления.
Недостатком объединенных списков является их удаленность от источника данных, и сложность исправления ошибок, внесенных на нижнем уровне.
Базы данных, как хранилища списков
Все вышесказанное о списках сообщалось прежде всего для того, чтобы обозначить управленческие функции и задачи, которые побуждают к созданию электронных баз данных под управлением специальных программ – систем управления базами данных (СУБД). А не наоборот, как порой можно слышать или видеть в средствах массовой информации, и, тем более, в рекламе СУБД. И это очень важно. «Счастье» не наступает от внедрения СУБД Oracle, MS SQL Server, PostgreSQL, или так популярных сейчас СУБД из категории NoSQL.
Вторым источником непонимания разработчиков и заказчиков информационных систем является различие в понимании того, что такое «качество» данных. Причина в том, как указывал Кристофер Дейт, что «Истинность и непротиворечивость — не одно и то же» [35 стр. 351]. Поставщики СУБД и разработчики баз данных продают инструмент поддержки непротиворечивости данных, а заказчики покупают хранилище правильных данных в том числе в форме списков. Обеспечение правильности (достоверности, актуальности) данных достигается организационными усилиями сотрудников, в первую очередь руководителей, организации, использующей информационную систему и правильным распределением модулей информационной системы по рабочим местам сотрудников.
Дополнительно смотри, например, «Электронное правительство: какие решать задачи?», «Одно окно»? — индикатор проблем управления, Двухслойная модель управления.
Третьим источником разочарования заказчика в информационной системе становится нацеленность разработчиков на использование базы данных предназначенной только для одной разработанной им информационной системы, называемой базой данных приложения [2 стр. 27]. Структура такой базы данных наилучшим образом согласована c функциональностью конкретной информационной системы, делая работу последней эффективной. Такой подход удобен разработчику, т.к. обеспечивает ему полный контроль над сопровождением и развитием базы данных. Но необходимость соединения списков, в том числе из разных информационных систем, требует, чтобы структура базы данных состояла из таблиц, каждая из которых соответствовала единственному понятию (сущности), обеспечивая при этом возможность комбинирования с другими таблицами.
Таким образом хранилище списков, которое одновременно используется специалистами различных уровней управления, должно содержать механизм регулярной синхронизации списков верхних уровней по мере изменения списков нижних уровней управления.
Как говорилось выше, иерархии управления соответствует иерархии списков. Когда хранение этих списков распределено по серии электронных баз данных на каждом уровне управления, то возникает риск, что данные по мере удаления мест их хранения от источников значительно теряют в актуальности (правильности, истинности). Продолжительность интервала потери актуальности списка называется окном несогласованности (inconsistency window) [2 стр.70].
Наличие окон несогласованности списков в базах данных на различных уровнях управления [Рис. 10], а также затраты на техническую поддержку баз данных на каждом уровне порождают желание хранить все данные списков на самом верхнем уровне управления. Дело в том, что функциональные возможности СУБД в совокупности с современными средствами связи позволяют одновременно хранить списки предназначенные для всех уровней управления.
Платой за желание централизовать данные в первую очередь станет сложность выявления и исправления ошибок в значениях списков.
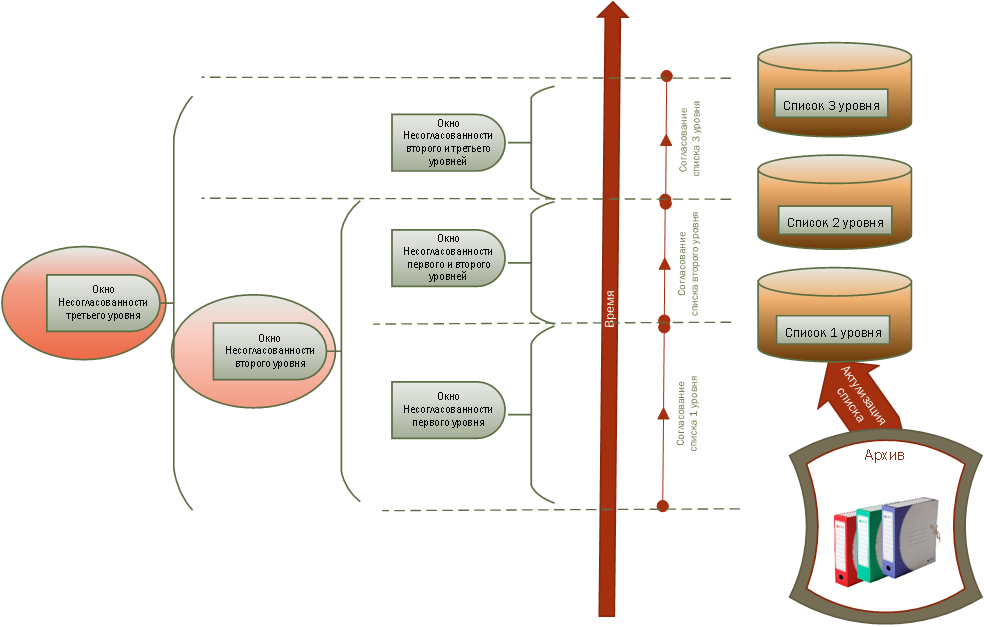
Рис. 10. Окна несогласованности списков иерархии управления.
Причиной сложности работы с ошибками в централизованном хранилище списков является невозможность смыслового управления большим объемом данных специалистами верхнего уровня и удаленность создателей этих данных. Примером централизованного хранилища списка является Государственный Адресный реестр Федеральной Информационной Адресной Системы. (Смотри также: «Эх, ФИАС, ФИАС… Почему ты не адресный реестр?», «Анализ адресов ФИАС»).
Централизация хранения списков всех уровней, часто приводит к тому, что характеристики списков оказываются несоответствующими задачам управления на других уровнях кроме верхнего. Причиной этого становится принцип минимальной длины описания (МДО) [23 стр. 9] в подходе к созданию списка, который обсуждался в предыдущих разделах. Поэтому на уровнях, где централизованный список оказывается с неполным набором характеристик создавать собственные дополнительные списки и связывать их по мере необходимости, при условии, что централизованный список ведётся в базе данных созданной в соответствии с требованиями к интеграционной базе данных, а не базе данных отдельного приложения.
Ложка дёгтя
Один знакомый, имеющий как знания в области создания информационных систем, так и опыт работы в министерстве информатизации Красноярского края, часто повторял, что данные органов власти по степени актуальности делятся на 3 части: 30% актуальных данных; 40% пригодных для отдельных случаев; 30% — мусор. А мусор на входе приводит к мусору на выходе. И это одна из объективных причин того, почему идея открытых данных не слишком популярна следи служащих государственных и муниципальных органов власти.
«Мусор» в данных организации появляется, чаще всего, в результате одноразовых межведомственных соединений списков, когда руководитель поставил задачу, решение которой не обеспечено нужными данными, а подчиненный нашел нужные данные через знакомых. Такие данные изначально могут быть неактуальными, а со временем из-за отсутствия регулярной процедуры их актуализации превращаются в «мусор».
Выше уже отмечались проблемы, мешающие качественному соединению списков, поэтому здесь они лишь повторены в одном меcте.
Проблема межведомственной несогласуемости списков создает серьезные препятствия на пути цифровизации экономики РФ в первую очередь потому, что органы ответственные за цифровизацию страны пока не рассматривают ее, как проблему.
Проблема отсутствия общих классификаторов и справочников, заключается в том, что справочники часто рассматриваются как внутренний вспомогательный ресурс организации, при этом игнорируется свойство классификаторов и справочников обеспечивать совместимость списков.
Проблема удаленности от источника данных. Степень актуальности данных списка ухудшается по мере его удаленности от источника данных.
Проблема не востребованности характеристик списка управленческими функциями. Степень актуальности данных списка ухудшается, если они не используются в процессе выполнения управленческих функций.
Можно с уверенностью сказать, что перечисленные проблемы стали причиной того, одностороннего внедрения системы межведомственного электронного взаимодействия (СМЭВ) [54]. В настоящее время СМЭВ активно используется для взаимодействия информационных систем с порталом государственных услуг, т.е. для взаимодействия с гражданами. Но для массового электронного взаимодействия между информационными системами необходимо решать не того инфраструктурные задачи, но и задачи согласованности списков этих систем.
Сноски
[*1] Смотри записи блога: «Адреса ФИАС в среде PostgreSQL» и «Дома ФИАС в среде PostgreSQL».
[*2] Письмо Рене Декарта аббату Мерсенну (20 ноября 1629 года). перевод с английского Гончарова Алина Алексеевна.
Смотри другие публикации из цикла «По следам забытого РЕГОСС»:
- Часть 1 Информационные системы
- Классификаторы для управленческих списков
- Приложение 1. Паутина балансодержателей
- Приложение 2. Имущество. Часть 1
- Приложение 2. Имущество. Часть 2
Литература
- Эрик Эванс. Предметно-ориентированное проектирование (DDD): структуризация сложных программных систем. Пер. с англ. — М.: 000 «И.Д. Вильямс», — 448 с. : ил.
- Мартин Фаулер, Прамодкумар Дж Садаладж. NoSQL: новая методология разработки нереляционных баз данных. Пер. с англ. — М.: ООО «И.Д. Вильяме», 2013. — 192 с.: ил.
- Нонако Икуджиро, Такеучи Хиротака. Компания — создатель знания. Зарождение и развитие инноваций в японских фирмах. Пер. с англ. А. Трактинского. — М.: ЗАО «Олимп-Бизнес», 2011. — 384 С.: ил.
- Иванов М.А., Шустерман Д.М. Организация как ваш инструмент: Российский менталитет и практика бизнеса. ‑3-е изд. – М: Альпина Бизнес Букс, 2006‑ 392 С.
- Саймон Герберт, Науки об искусственном: Пер с англ. Изд. 2-е. — М.: Едиториал УРСС, 2004. — 144 с.
- Бир Стаффорд, Кибернетика и управление производством. Мифология систем под сводом сумерек. /Под ред. А.Б. Челюсткина. Пер. с англ. Изд. 2-е. М: Издательство «НАУКА», 1965. – 392 с.
- Бир Стаффорд, Кибернетика и управление производством.Пер. с англ. Изд. 2-е. М: Издательство «НАУКА», 1965. – 392 с.
- Сенге Питер, Танец перемен: новые проблемы самообучающихся организаций/ Питер М. Сенге, Арт Клейнер, Шарлота Робертс, Ричард Б. Росс, Джорж Рот, Брайан Дж. Смит// Пер. с англ. Борис Пинскер М: Издательство «Олимп-Бизнес», 2017. – 624 с.: ил
- Сенге Питер, Пятая дисциплина. Искусство и практика обучающейся организации/ Пер. с англ. Константинова Юлия М: Издательство «Манн, Иванов и Фербер», 2018. – 496 с.: ил
- Карр Николас Дж. Блеск и нищета информационных технологий: почему ИТ не являются конкурентным преимуществом. /Пер. с англ. М: Издательский дом «Секрет фирмы», 2005– 176 с.
- Гамма Э., Хелм Р., Джонсон Р., Влиссидес Дж , Приемы объектно-ориентированного проектирования. Паттерны проектирования. — СПб: Питер, 2001. — 368 с.: ил. (Серия ≪Библиотека программиста≫)
- Аристотель, Метафизика. Сочинения в четырех томах. Т. 1. Ред. В. Ф. Асмус. М., «Мысль», 1976.550 с.; (АН СССР. Ин-т философии. Филос. наследие). Стр. 63.
- Когаловский М. Р., Перспективные технологии информационных систем. — М.: ДМК Пресс, 2003, — 288 с.
- Глушков В.М. Основы безбумажной информатики. Изд. 2-е, испр.‑ М.: Наука. Гл. ред. физ.-мат. лит., 1987. ‑ 552 с.
- Джордж Л. Майкл «Бережливое производство + шесть сигм» в сфере услуг: Как скорость бережливого производства и качество шести сигм помогают совершенствованию бизнеса / Майкл Л. Джордж; [пер. с англ.] — М.: Альпина Бизнес Букс, 2005. — 402 с. — (Серия «Модели менеджмента ведущих корпораций»).
- Пихорович В.Д. «Очерки истории кибернетики в СССР». Изд. Стереотип. М.: ЛЕНАРД, 2016. – 264 с. (Наука в СССР: Через тернии к звездам. № 31.)
- Фреге Готлоб, О Смысле и Значении, стр. 230-246. Логика и логическая семантика: Сборник трудов/Пер. с нем. Б.В. Бирюкова под ред. З.А. Кузичевой: Учебное пособие для студентов вузов. М.: Аспект Пресс. 2000 – 512с.
- Фреге Готлоб, Размышления о Смысле и Значении, стр. 247-252. Логика и логическая семантика: Сборник трудов/Пер. с нем. Б.В. Бирюкова под ред. З.А. Кузичевой: Учебное пособие для студентов вузов. М.: Аспект Пресс. 2000 – 512с.
- Фреге Готлоб, О Функции и Понятии, стр. 215-228. Логика и логическая семантика: Сборник трудов/Пер. с нем. Б.В. Бирюкова под ред. З.А. Кузичевой: Учебное пособие для студентов вузов. М.: Аспект Пресс. 2000 – 512с.
- Фреге Готлоб, О Понятии и Предмете, стр. 253-262. Логика и логическая семантика: Сборник трудов/Пер. с нем. Б.В. Бирюкова под ред. З.А. Кузичевой: Учебное пособие для студентов вузов. М.: Аспект Пресс. 2000 – 512с.
- Акаткин Ю.М., Ясиновская Е.Д. Цифровая трансформация государственного управления: Датацентричность и семантическая интероперабельность / Под науч. Ред. И предисл. В.А. Конявского. – М.: ЛЕНАНД, 2019 – 724 с.
- Лайонз Дж. Введение в теоретическую лингвистику. — М.: Прогресс, 1978. — 544 с.
- Потапов А.С., Распознавание образов и машинное восприятие: Общий подход на основе принципа минимальной длины описания. – СПб.: Политехника, 2011. – 548 с.: ил.
- Ансофф И. Стратегическое управление. М Экономика. Пер. с англ. – М.: Экономика, 1989. –520 с.
- Родионов В.И. Регулирование динамики социально-экономических систем в условиях роста нестабильности внешней и внутренней среды. М Спб «Нестор-История», 2012. –394 с.
- Паттон Джефф, Пользовательские истории. Искусство гибкой разработки ПО. — СПб.: Питер, 2017. — 288 с.: ил. — (Серия «Бестселлеры O’Reilly»).
- Лосев Алексей Федорович, Философия имени. Бытие. Имя. Космос / Сост. и ред. А.А.Тахо-Годи — М: Мысль,1993.958 с. Стр.613.
- Борхес Хорхе Луис, Аналитический язык Джона Уилкинса, Сочинения в трех томах. Т.2/Пер. с исп.; Составл., предисл., коммент. Б. Дубина. – Рига: Полярис, 1994. ‑511с. Стр. 85.
- Гегель Георг Вильгельм Фридрих, Наука Логики, В 3-х томах. Т.1/ Пер. с нем. Б. Г. Столпнера. – М: «Мысль», 1970. ‑501с. (АН СССР. Ин-т философии. Философское наследие).
- Гегель Георг Вильгельм Фридрих, Феноменология духа/ Пер. с нем. Г. Шпета. – М: Наука, 2000. -495 с. (Российская АН. Ин-т философии. Серия «Памятники философской мысли»).
- Эшби У. Росс, Введение в кибернетику, М:«Иностранная литература», 1959 — 432 с.
- Ингерсолл Грант С., Мортон Томас С., Фэррис Эндрю Л., Обработка неструктурированных текстов. Поиск, организация и манипулирование. / Пер. с англ. Слинкин А.А. – М.: ДМК Пресс, 2015. – 414 с.: ил.
- Омельченко В.В. Общая теория классификации. Часть I. Основы системологии познания действительности. М.: ООО «ИПЦ „Маска»», 2008 — 436 с.
- Омельченко В.В. Общая теория классификации. Часть 2. Общая теория классификации. Ч. 2: Теоретико-множественные основания /Предисл. Д. А. Ловцова. — М.: Книжный дом «ЛИБРОКОМ», 2010. — 296 с.
- Дейт К. Дж. Введение в системы баз данных = Introduction to Database Systems. — 8-е изд. — М.: Вильямс, 2005. — 1328 с.
- Кузнецов С. Д. Основы баз данных. — 2-е изд. — М.: Интернет-университет информационных технологий; БИНОМ. Лаборатория знаний, 2007. — 484 с.
- Войшвилло Е. К. Понятие как форма мышления: логико-гносеологический анализ. — М.: Изд-во МГУ, 1989. — 239 с.
- Гладков Сергей, Разработка программ: проблемы и иллюзии. Открытые системы. СУБД 2010 № 01 c. 54. Дополнительно: Почему ИТ оказываются невостребованными и как этому способствуют программисты.
- Гладков Сергей, «О стратегическом подходе к развитию ИТ-отрасли Красноярского края»
- Гладков Сергей, «Оправдание технического задания»
- Гладков Сергей, Игра на третьей волне с благодарностью к «Красноярск.Биз»
- Нагаев Р.Т. Недвижимость: Энциклопедический словарь. – Казань: Издательство ГУП «Идел- Пресс», 2003. 1088-1.
- Федеральный закон от 25.06.2002 N 73-ФЗ (ред. от 21.02.2019) «Об объектах культурного наследия (памятниках истории и культуры) народов Российской Федерации»./
- Закон Красноярского края от 17 января 1996 г. № 8-220 «Об управлении государственной собственностью Красноярского края» (действующая версия: Закон Красноярского края от 03 марта 2011г. № 12-5650 «Об управлении государственной собственностью Красноярского края»)
- Постановление администрации Красноярского края от 16 февраля 2000 г. N 101-П «Об утверждении Положения об учете государственного имущества Красноярского края и ведении Реестра государственной собственности Красноярского края» (действующая версия: Постановление Правительства Красноярского края от 15 декабря 2014 № 594-п «Об утверждении Правил ведения Реестра государственной собственности Красноярского края»)
- Постановление Правительства Российский Федерации от 3 июля 1998 г. № 696 «Об организации учета федерального имущества и ведения реестра федерального имущества» (действующая версия: Постановление Правительства Российский Федерации от 16 июля 2007 г. № 447 «О совершенствовании учета федерального имущества»
- Приказ Министерства экономического развития РФ от 30 августа 2011 г. N 424 «Об утверждении Порядка ведения органами местного самоуправления реестров муниципального имущества»
- Распоряжение Минэкономразвития России от 14.04.2014 N 26Р-АУ «Об утверждении Методических рекомендаций по внедрению проектного управления в органах исполнительной власти»
- Приказ Министерства финансов РФ от 1 декабря 2010 г. N 157н » Единого плана счетов бухгалтерского учета для органов государственной власти (государственных органов), органов местного самоуправления, органов управления государственными внебюджетными фондами, государственных академий наук, государственных (муниципальных) учреждений и Инструкции по его применению (с изменениями на 28 декабря 2018 года)»
- Закон Красноярского края от 30 июня 2003 года N 7-1195 О краевой целевой программе «Создание автоматизированной системы ведения государственного земельного кадастра и государственного учета объектов недвижимости в Красноярском крае на 2003-2007 годы»
- Приказ Красноярского краевого комитета по управлению государственным имуществом от 7 мая 2003 года N 09-288п «Об утверждении правил учета государственного имущества на территории Красноярского края».
- Инструкция Госкомстата России 22.12.1999 N АС-1-24/6483 «о порядке учета юридических лиц, их обособленных подразделений в Едином государственном регистре предприятий и организаций. Часть I».
- Счетная палата Красноярского края. АКТ проверки эффективности управления и законности использования в 2009 году и I полугодии 2010 года объектов недвижимости, находящихся в оперативном управлении краевых государственных учреждений Красноярского края, от 11 октября 2010 г.
- Постановление Правительства Российский Федерации от 8 сентября 2010 г. N 697 «О единой системе межведомственного электронного взаимодействия».
Смотри другие публикации из цикла «По следам забытого РЕГОСС»:
- Часть 1 Информационные системы
- Классификаторы для управленческих списков
- Приложение 1. Паутина балансодержателей
- Приложение 2. Имущество. Часть 1
- Приложение 2. Имущество. Часть 2